
AI 对战街霸 II:GPT-3.5 真的比 GPT-4.0 更强大吗?
AFL 开张第一篇:写在前面
2023 年 7 月底,「AI 未来实验室」 1 个星期内便完成实验室 4 人团队的组建。8 月份开始,我们用了 2 个星期即完成第一个研究案例的大部分测试和评估工作。作为实验室媒体总编,笔者从来没感到过如此幸运,也特别感谢「AFL 委员会」的各位大佬。
AFL 首期拆解的案例中,我们的新团队参考 KOL 提供的探索路线,从对比 GPT 3.5 和 4.0 的角度,详细拆解了实现过程,最亮点的发现是:人类程序员可以借助 GPT 这个「大聪明」来快速帮助选择一个「小聪明」,并通过适当的训练尝试打败游戏里的各大 boss。
比较习惯视频的同学可以看这里:
想了解本案例背后的人工智能应用原理的同学们,可以继续往下看。
为什么选 AI vs.「街头霸王 II」

选这个案例起步 AFL 新团队的人工智能研究其实纯属偶然。首先要感谢 林亦LYi 同学为制作「格斗之王!AI写出来的AI竟然这么强!」的倾情投入。AFL 团队看了这个案例后立刻着手准备:我们顺着 林亦LYi 的故事线,但又不局限于此来调整我们评测的方向和角度,因为 AFL 执着于「拆解」人工智能背后的一切。于是我们的角度源自 2 个基本问题:
- 为什么评估 ChatGPT 时选择它辅助开发《街头霸王 II》AI 玩家?
- 为什么要将 ChatGPT 与这个开发过程相结合?
我们将《街头霸王 II》作为一个简单的例子,以检查在自动化控制条件下使用 AI 需要投入怎样的工作量和资源。想象一下,我们想创建一个服务,其中 AI 通过视频游戏进行播放并在线流式传输,因为越来越多的人更喜欢观看游戏故事,而不是花时间自己玩游戏。
为什么选择 ChatGPT?
由于 ChatGPT 迅速增长及其受欢迎程度,以及关于 GPT 作为一个强大、互动型智能助手的大量积极推荐,我们决定结合上述课题开展验证。
当我们开始调查时,我们遇到了第一个问题,
「我们应该使用哪个版本的 ChatGPT,3.5 还是 4?」
是的,这并不难理解,因为付费版本应更先进,但它在提供我们需要的协助方面到底有多好呢?因此,我们测试了两个不同的 GPT 版本,3.5 和 4,并两次都用 ChatGPT 重复同一个过程且都击败了《街头霸王 II》的大 boss 。
ChatGPT 版本的比较
为方便评估,我们向两个 GPT 版本提出了完全相同的问题,并按照相同的顺序提出,同时还使用了2个独立的账户来验证 GPT 是否没有在 GPT 3.5 和 4 之间的相似主题下缓存响应。
经过与不同模型的大量交流后,我们发现:
- 为了让 GPT 全面协助我完成任务,以便我制作所需脚本的第一个版本,我需要向 GPT 3.5 提出 7 个问题,而对于 GPT 4 我只需要提出 4 个问题。
- 另一个显著的差异我们很难用量化方式来比较和解释,感觉就像使用 GPT 4 提问时,我们可以不那么具体,但仍可以得到期望的结果。
- 这两个版本之间的最后一个区别是:OpenAI 官方用来更新的通用知识库数据集训练 GPT 4。
我们开始吧:用 AI 开发「机器人游戏玩家」
问题一:准备环境
在当前稳定的 Python 版本 3.11 下,用于运行和控制复古游戏的库,Gym-retro,就无法安装,GPT 无法为这个问题提供解决方案,两个模型都建议将 Python 和包管理器升级到最新版本。但实际的解决方案恰恰相反,我们需要将我们的 Python 环境和工具降级到较旧的版本,因为这个控制复古游戏的代码库已经三年没有维护了。
问题二:GPT 提供了「差不多」的结果
仅仅要求 ChatGPT 为你编写脚本并不能提供关键的解决方案,还需要理解强化模型是如何工作的原理。两个版本的 GPT 都能提供强化学习的概述描述,但我们仍然需要使用搜索引擎和文档来更好地理解它是如何工作的,以便进行适当的调整并用适当的请求来向 GPT 提问。
问题三:GPT 帮选了个小模型,我们训练这个小模型打游戏
最终,GPT 帮我们从一个现成的神经网络小模型库 PyTorch 中选出了一个叫 PPO 、参数只有 2 千多的小模型。我们于是借助 GPT 协助开发的机器人玩家脚本程序,其中植入了 PPO 模型并对其进行了打游戏训练。尽管如此,我们只找到了一些仅在通过游戏的 boss 或第一关的一个场景上进行训练的模型。
虽然我们借助 GPT 快速从 PyTorch 中选出 PPO 小模型用于本测试;但是,训练这个小模型去打败大 boss 并通关,需要很长时间。如果我们谈论的是标准家用计算机,那么预计耗费的时间按「要几周」来算。因为训练一个合适的强化模型需要大量的参数调整,以及对同一游戏情境的多次重复实验。
演示视频:训练机器人玩家
结论
高复杂度
创建自己的强化学习模型对于非技术人员来说复杂性太高,因为它需要深入理解 AI的学习过程及其背后的工作原理,而且需要对激励系统做出适当的自然语言描述,在所有可能的场景中进行多次模型训练。我不能说学习这个概念很复杂,事实并非如此。但是,没有很多人能够为 AI 代理准备适当的描述,以明确我们需要为哪些方面提供激励和惩罚,而且激励系统描述得越细致,最终能够获得的结果就越好。
这个套路的另一个缺点是对计算机硬件的要求非常高,这可能阻止很多人尝试这种特别有针对性的 AI 代理模型和训练方法,因为没有很多人愿意为了尝试训练模型而让他们的计算机 24/7 运行。
即使我们使用了参考文献中的预训练模型,这些 AI 代理也只被训练成做一件事——击败最终 boss 或特定的游戏关卡,而且它无法一个模型一次过训练达到让机器人玩具通关整个游戏。
所以,上述训练方案和技术更适合企业或狂热的用户。
硬件限制
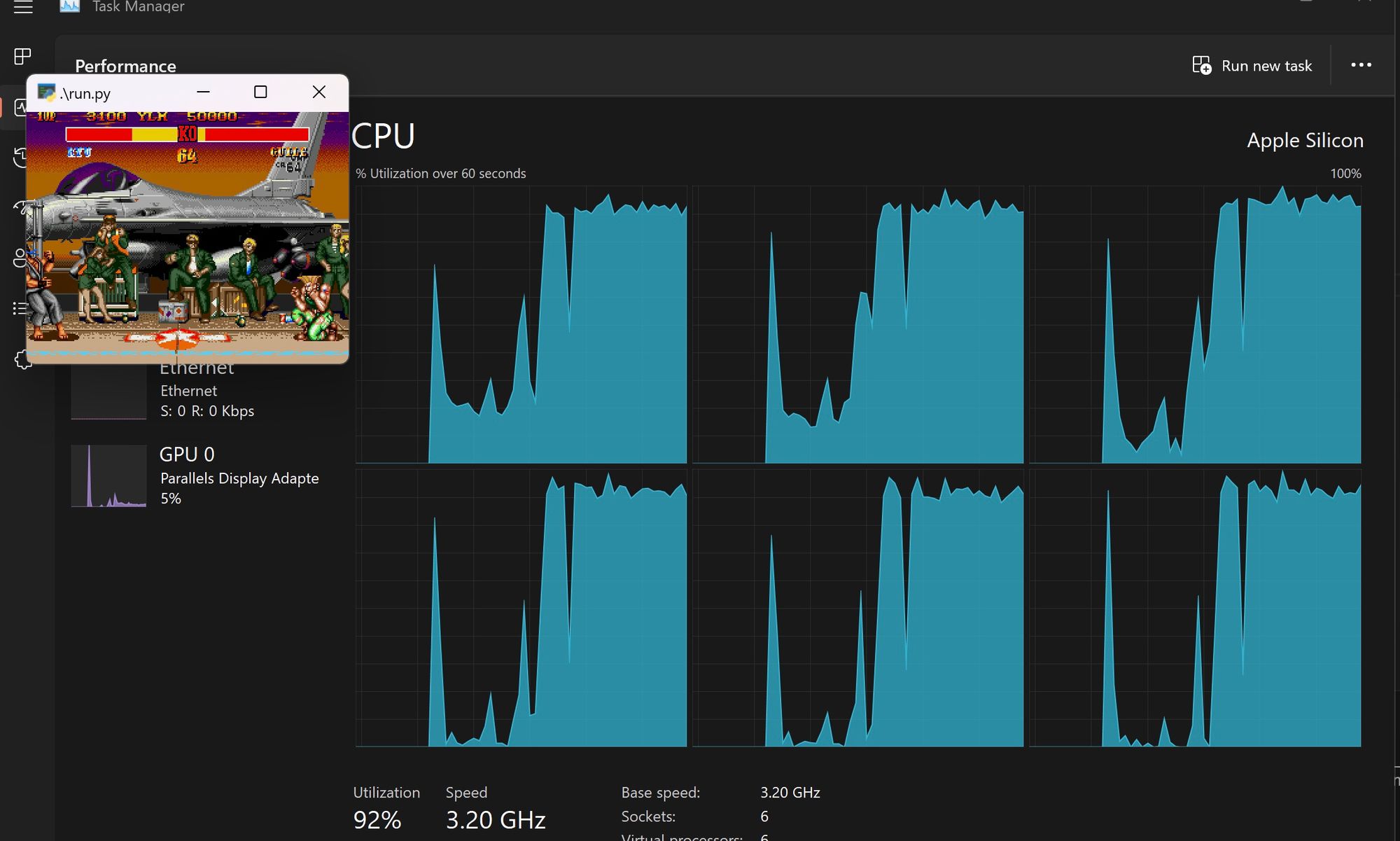
我们不仅在模型训练时遇到了硬件限制,而且在使用它时也遇到了。例如,在没有AI 加速器的计算机上执行最终的 AI 程序,即使对于那个简单的游戏,它也会占用所有 CPU 的 93%~98% 的资源。
ChatGPT 作为助手
在本研究案例中,ChatGPT 表现得非常有前途,两个 GPT 版本都能够帮助实现最终结果。只是使用 GPT 4,结果达到得更快,它可以接受更一般性的问题,而对于GPT 3.5,你确实需要提供更多的细节才能得到适当的答案。
在两种情况下,我们都无法直接使用 GPT 生成的代码,我们需要进行小的调整才能使其工作,但这些调整可以描述为替换值或修改库名,因为它使用了错误的模块名。
总体而言,ChatGPT 是一个很棒的工具,可以大大加快开发游戏的机器人玩家脚本的工作速度。我们推荐在人们至少具有一定 AI 专业知识的主题上才使用它,以便能够识别出 GPT 因其「幻觉」而产生的错误信息。对于非专家用户,我们建议在请求生成某些实现之前,先从 GPT 聊天开始,询问一些理论参考资料。
ChatGPT 3.5 还是 4.0?
那么,在什么情况下使用哪个版本更好呢?
如果用户已经对主题有一定的了解,并能够即时识别错误,那么 GPT 3.5 是一个不错的选择。对于所有其他用户,我们推荐使用 GPT 4,因为它是基于最新的数据集进行训练的,能够理解您一般性地提出的问题。
后记
利用 AI 未来实验室的首个人工智能评测案例,我们快速完成了新团队的协同与磨合,坚定了我们对 AFL 使命的认可:我们致力于探索人工智能(AI)未来和其对社会的影响。
AFL 选择通过十分具体的案例,避免堆砌抽象的理论以及对各种概念的泛泛而谈。如果你喜欢「AI 未来实验室」的内容输出风格,而且也相信只有这样才能让更广大的技术和非技术背景用户获得第一手的、深度的、具体的人工智能应用价值分析,那么请继续关注我们的官网并邮件订阅我们的最新报告和更新。
我们下期再见!


